Построение байтового дерева для сверхбыстрого поиска.
| Раздел Подземелье Магов | е дамы и господа, наконец, настало время, когда я решил написать статью, обещанную королевству около года назад. Зараннее извиняюсь за свой стиль, давно не приходилось писать что-нибудь большое на руском. Поводом к написанию статьи стали результаты моего решения для оптимизации поиска. Я приведу конкретную задачу, но использовать данную технологию поиска можно во многих задачах.
Задача формулировалась так: Имеется список звонков или один звонок. Item - это элемент дерева от 0 до 9
Я выбрал динамический массив для хранения дерева как наиболее удобный и экономичный способ хранения. При использовани масива мы икономим 2 байта на указателе, это накладывает ограничение на количество элементов масива 65535. Если необходимо больше, то можно заменить индекс адресом. Но при этом обций размер масива увеличится в 3-4 раза. 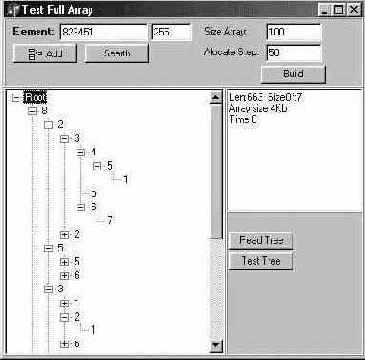 При таком посторении дерева экономится память. То есть, для нахождения тарифа 82345 надо сделать 4 шага от корня и при каждом шаге проверять содержание дочерних элементов для нахождения нужной ветки. Если при построении дерева встречаются два похожих тарифа типа 82346, то добавляется только узел 6. Этим экономится много памяти. Все остальное вместе с примерами можно найти в архиве. Там релизован класс TsmallTree который имеет необходимые методы procedure AddArray(Var Tarif: Array of ShortString); строит дерево из массива procedure AddElement(Key: ShortString; ID: Cardinal); function Find(Key: ShortString): Word; procedure RecursiveBeat(AProc: TBuildNode); создает указатель на процедуру. procedure ShowTree; - вызывает эту процедуру для каждого узла(я использовал при отладке) В секцию public вынесены две переменные Step: Word; - а это как следует из названия шаг увеличения памяти. List: Array of sNode; - это само дерево Поскольку при построении дерева количество элементов обычно больше 100, то невыгодно прибавлять по 1 элементу (очень медленно). Поэтому я сделал, как обычно в этих случаях, свой менеджер, который при превышении границы массива прибавляет N элементов. Я советую величину шага ставить на порядок меньше элементов масива. То есть Array:1000 Step:100, Array:10000 Step:1000 , тогда нет торможения программы. У меня при 10000 элементах все работало нормально, но при 12000 начинались какие-то проблемы, возможно, это связано с теоретическим пределом в 65535 узлов дерева. В описании упоминаются два массива - один массив строк (исходный материал для построения), другой масив - это само дерево, не перепутайте!
Скачать файлы проекта :
|
table WIDTH="100%" BGCOLOR="#FAEBD7" CELLPADDING="3" CELLSPACING="0" >
